
Sentita, a sentiment analysis tool for Italian
Hello, in this post want to present a tool to perform sentiment analysis on Italian texts. While I was working on a paper where I needed to perform sentiment classification on Italian texts I noticed that there are not many Python or R packages for Italian sentiment classification. Those that are available in most of the case are rule based and, in my case, didn’t handle correctly negations and synonyms. The fact that most of the open source tools available are rule based and rely on dictionaries is not surprising due to the scarcity of datasets for sentiment analysis in Italian. One option is to translate sentences in English and perform the sentiment analysis in English. This often works well considering the quality achieved by translational models. Unfortunately, it requires translating every text and if the quantity of text is very large it can become expensive (e.g. using Google translate API from Google Cloud). Moreover, for specific types of texts like tweets or online reviews where the language style is less formal translational models perform worse and thus it would be better to perform the sentiment analysis in the original language.
The dataset
In order to train a machine learning model for sentiment classification the first step is to find the data. Searching through the web I discovered a few datasets (Sentipolc2016 and ABSITA2018) on Italian sentiment analysis coming from the Evalita challenge that is a data challenge held regularly in Italy to evaluate the status of the NLP research on Italian. Combining them together after some pre-processing to homogenise the data I ended up with around 15,000 positively and negatively labelled sentences. This number of sentences starts to be enough to train a deep learning model (or at list to try). To train the model properly, it is necessary to provide also some neutral examples, otherwise the model will be always outputting either positive or negative for each sentence. To obtain a large number of sentiment neutral sentences I took an extract of around 90,000 Wikipedia sentences and automatically labelled all of them as neutral. This is an approximation, but it’s true that most of Wikipedia sentences are sentiment neutral, so the noise introduced in the labels is very small and the benefit of having 90,000 more neutral examples overcomes it. Summarizing, the dataset available to train and test the model comprises c.a. 102k sentences of which 7k positives, 7k negatives and 88k neutral.
The model
The deep learning model applied is a Bidirectional LSTM-CNN that operates at word level. The model receives in input a word embedding representation of the single words and outputs two signals ranging between 0 and 1, one for positive sentiment detection and one for negative sentiment detection. The two signals can be triggered both by the same input sentence if this contain both positive and negative sentiment (e.g. “The food is very good, but the location isn’t nice”). The model has a reduced number of trainable parameters, around 51k, and dropout to reduce overfitting. Currently the model can handle texts of length up to 35 words. The model is written in Python 3.6 and is implemented in Keras 2.2.4 with Tensorflow 1.11 backend. Here you can see the model scheme in the picture.
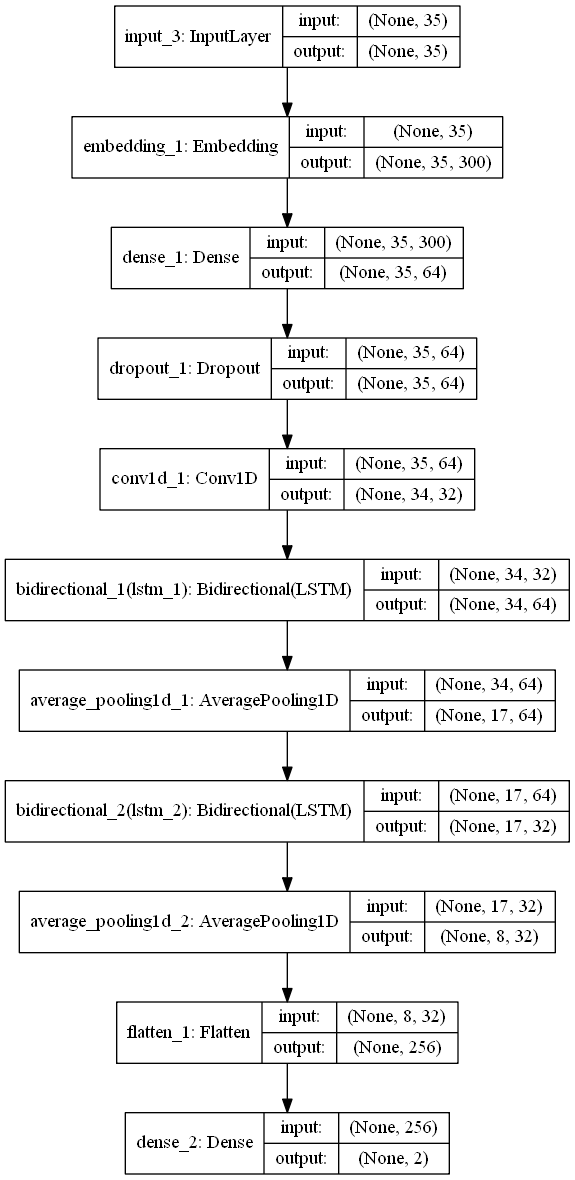{kind=link}
Sentita package
The Sentita python package contains the model and the necessary pre-processing functions. It is really simple to use and can be downloaded from this link
How to install Sentita:
- Unzip the .zip archive
- cd into the unzipped folder from the console
- type in the terminal/console “pip install .” to install the package locally
How to use Sentita:
- Import the function to calculate the polarity scores with the following code:
from sentita import calculate_polarity
- Define your sentences as a list. e.g.:
sentences = ["il film era interessante",
"il cibo è davvero buono",
"il posto era davvero accogliente e i camerieri simpatici, consigliato!"]
- Estimate the sentence polarity by running:
results, polarities = calculate_polarity(sentences)
“results” is a list of strings with the sentence, the positive polarity score and the negative polarity scores. “polarities” is a list of lists with the positive and negative polarity score for each sentence, e.g.:
- polarities[0][0] contains the positive polarity score of the 1st sentence
- polarities[2][0] contains the positive polarity score of the 3rd sentence
- polarities[2][1] contains the negative polarity score of the 3rd sentence
Sentita 0.2.0 is an alpha version and has been tested with Keras 2.2.4, Tensorflow 1.11 and Sapcy 2.0. In case you have any feedback feel free to contact me and let me know if you find Sentita useful